Анализ big-data с пикабу
Доброго времени суток! Эта статья о том как я попробовал себя как data science инженер. Для начала нам понадобиться: достаточно мощное железо, знания python3 и SQL запросов на базовом уровне и ведро терпения.
Чтобы не собирать данные вручную я решил взять готовый датасет с пикабу
Выбранный мной датасет находился в формате jsonl (большой json файл), для начала работы нам нужно перегнать данные в SQLite таблицу чтобы мы могли быстро выполнять множество интересующих нас запросов.
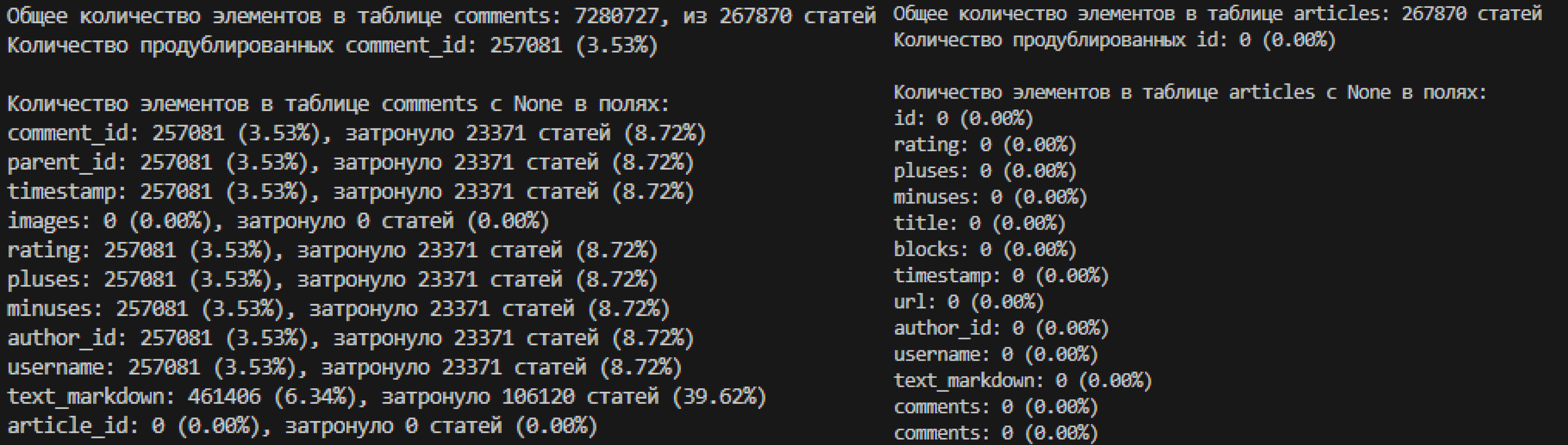
После перегонки SQL таблица весит 2.7гб, при этом изначальный файл весил 4.7гб.
Так как я хотел проанализировать данные через нейросети (недопустимое содержание, эмоция) я взял в еще одну таблицу первые 870к комментариев (для относительной быстроты анализа) и удалил все поврежденные записи.
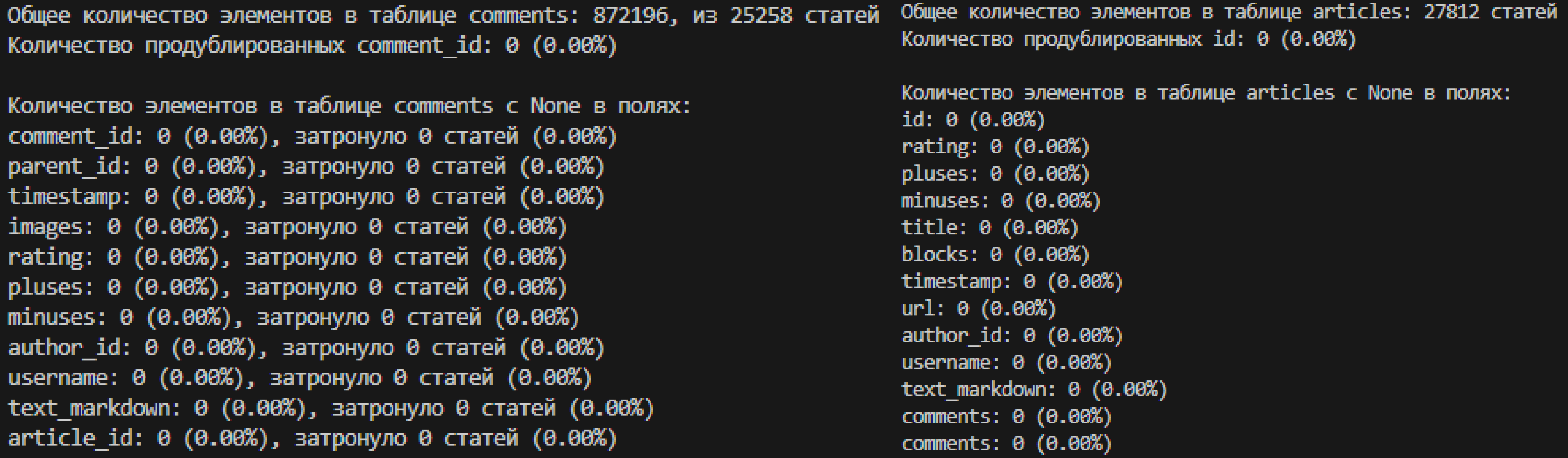
Анализ всех комментариев занял на моём ноутбуке около недели, но когда все готово можно приступить к анализу.
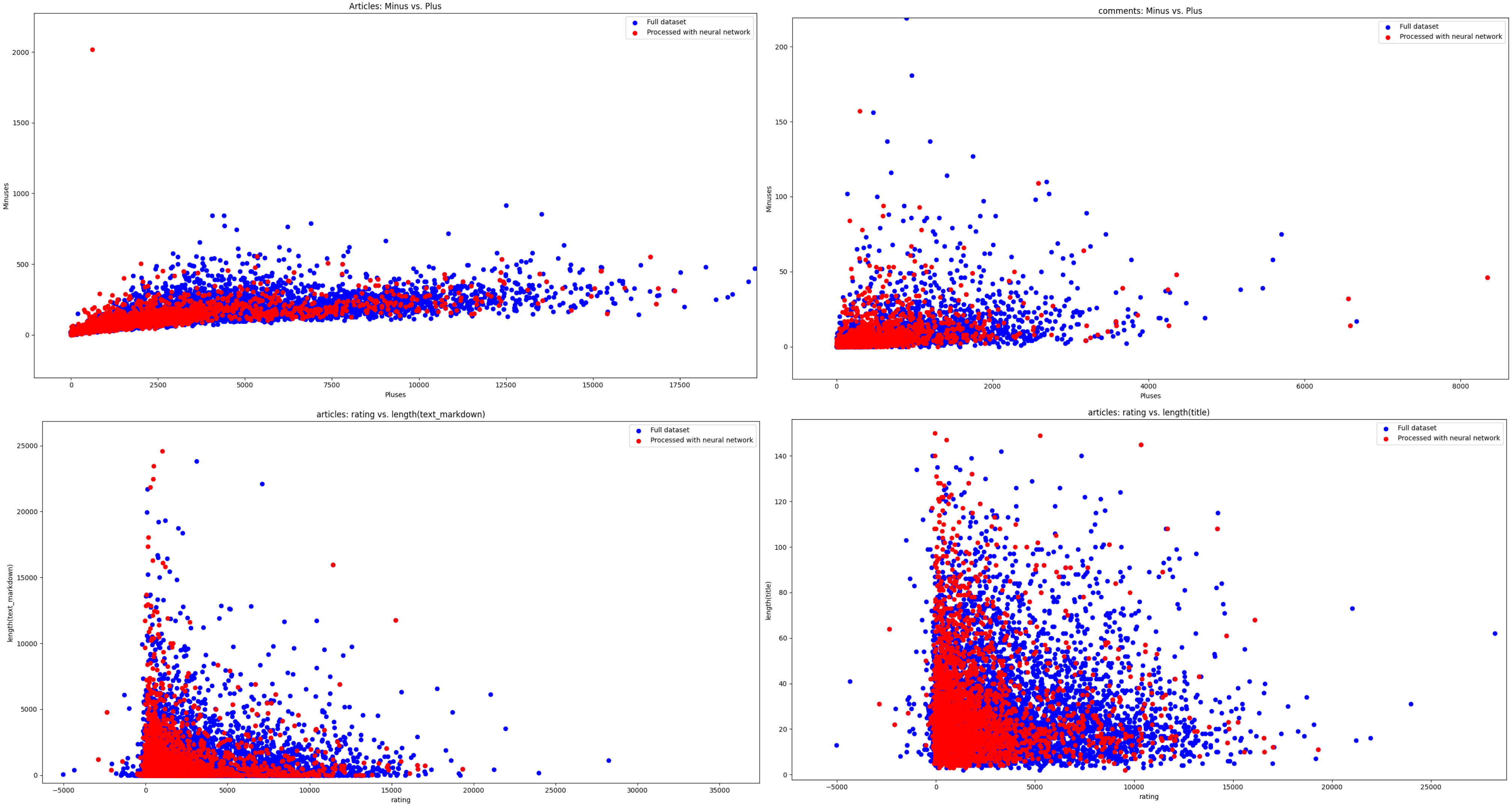
Статьи непропорциональна много собирают лайков, в сравнении с комментариями под ними. Так же можно предположить, что если вы хотите собрать побольше положительных оценок, заголовок вашей статьи должен быть около 20 символов, а размер самой статьи не более 2000 символов.
На пикабу у статей есть теги и самые популярные из них:
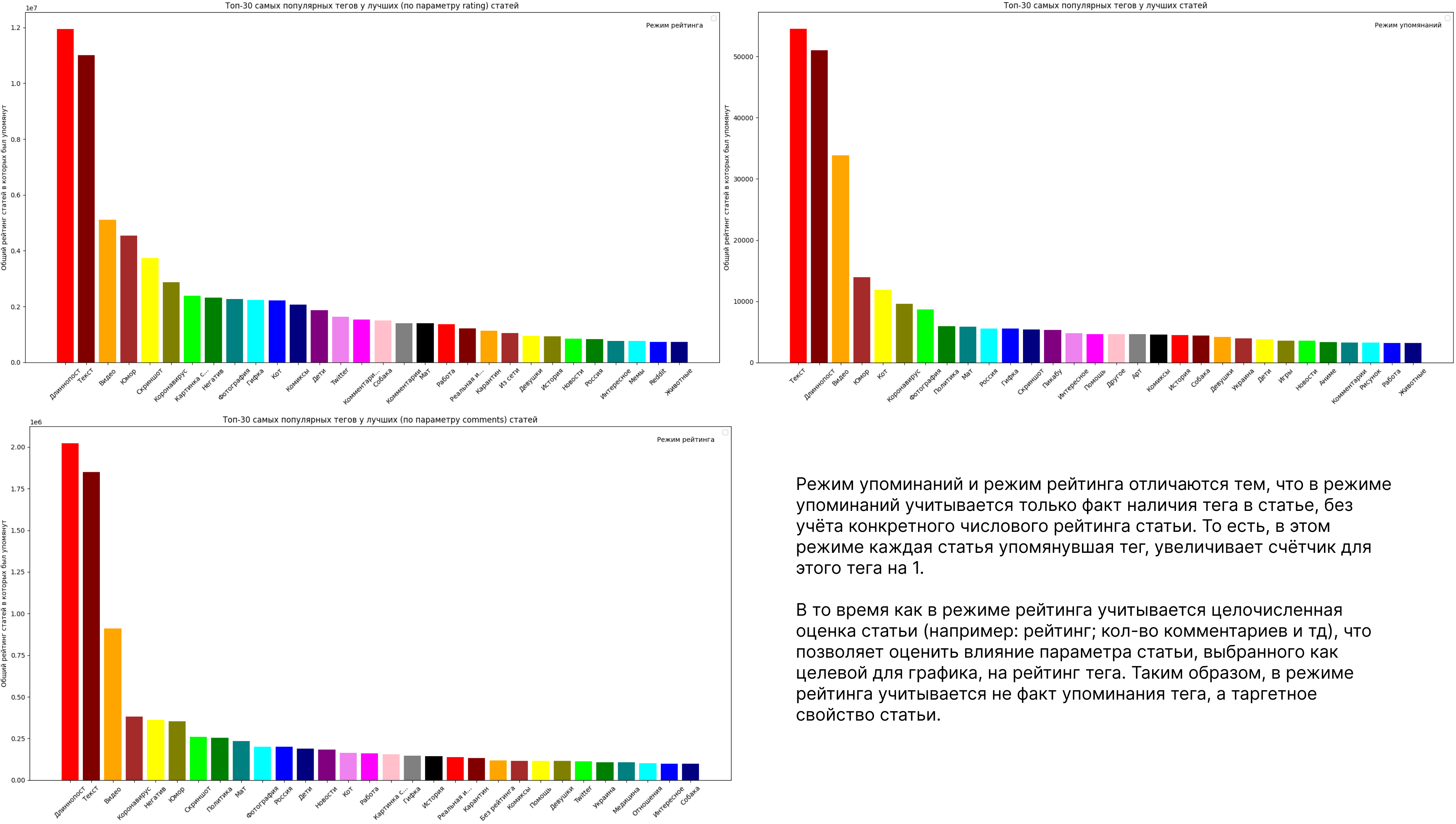
Три титана на первых местах сместить не удалось ни одной таблице, а дальше можно и порассуждать. Самые используемые (после трех титанов) теги это “юмор”, “кот”, “коронавирус”, самые обсуждаемые статьи с тегами “коронавирус”, “негатив”, “юмор”, с самым высоким рейтингом “юмор”, “скриншот” и “коронавирус”.
Все теги кроме коронавируса обуславливаются спецификой площадки где всегда в топе куча мемов за +300. Коронавирус же просто был инфоповодом в 2020 году (немного контекста о датах комментариев и статей):
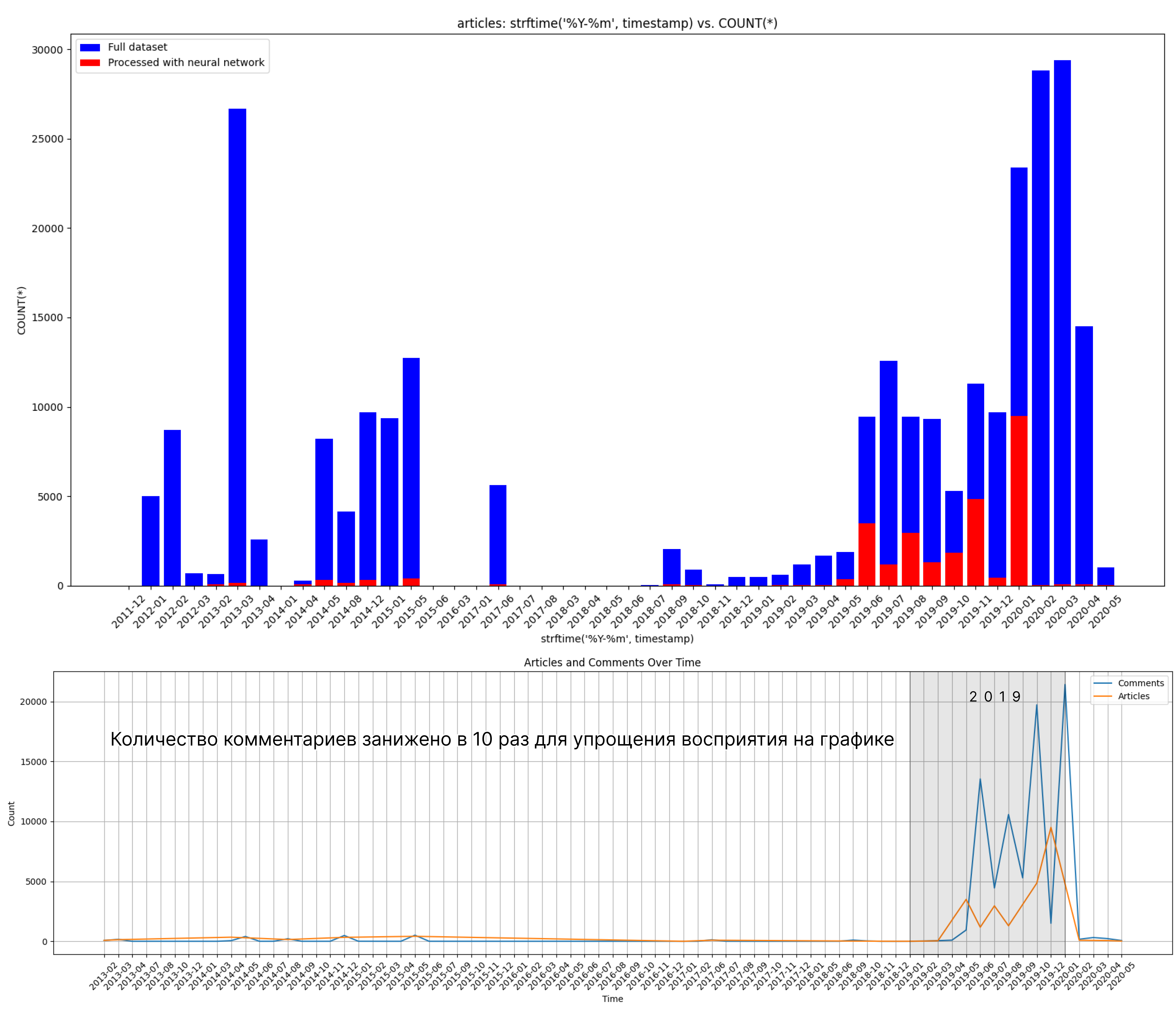
К сожалению люди не так часто собирают интересные датасеты для анализа, из-за чего пришлось взять достаточно устаревшую базу (самому собирать данные слишком долго и нудно).
Пройдемся по эмоциям:
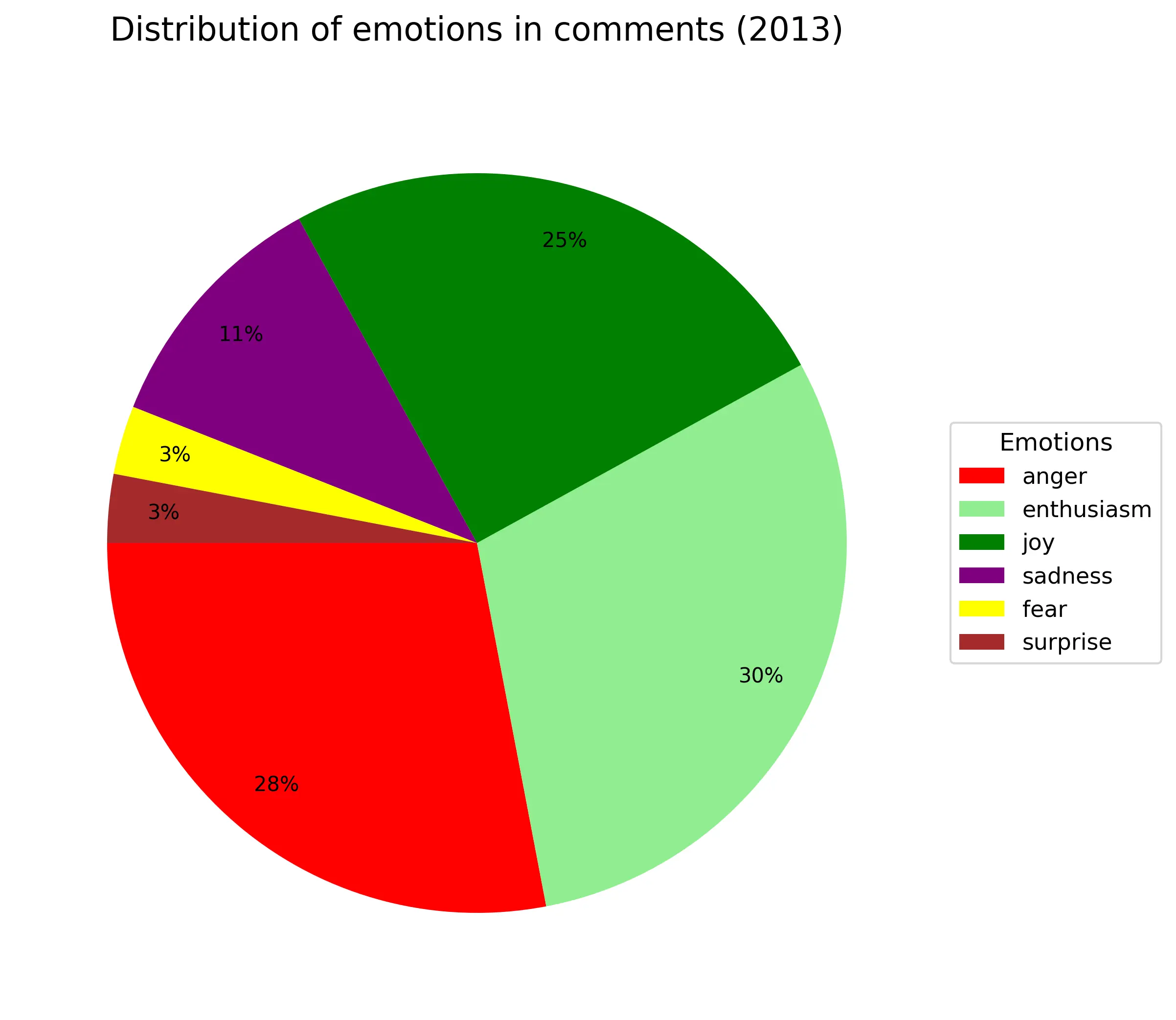
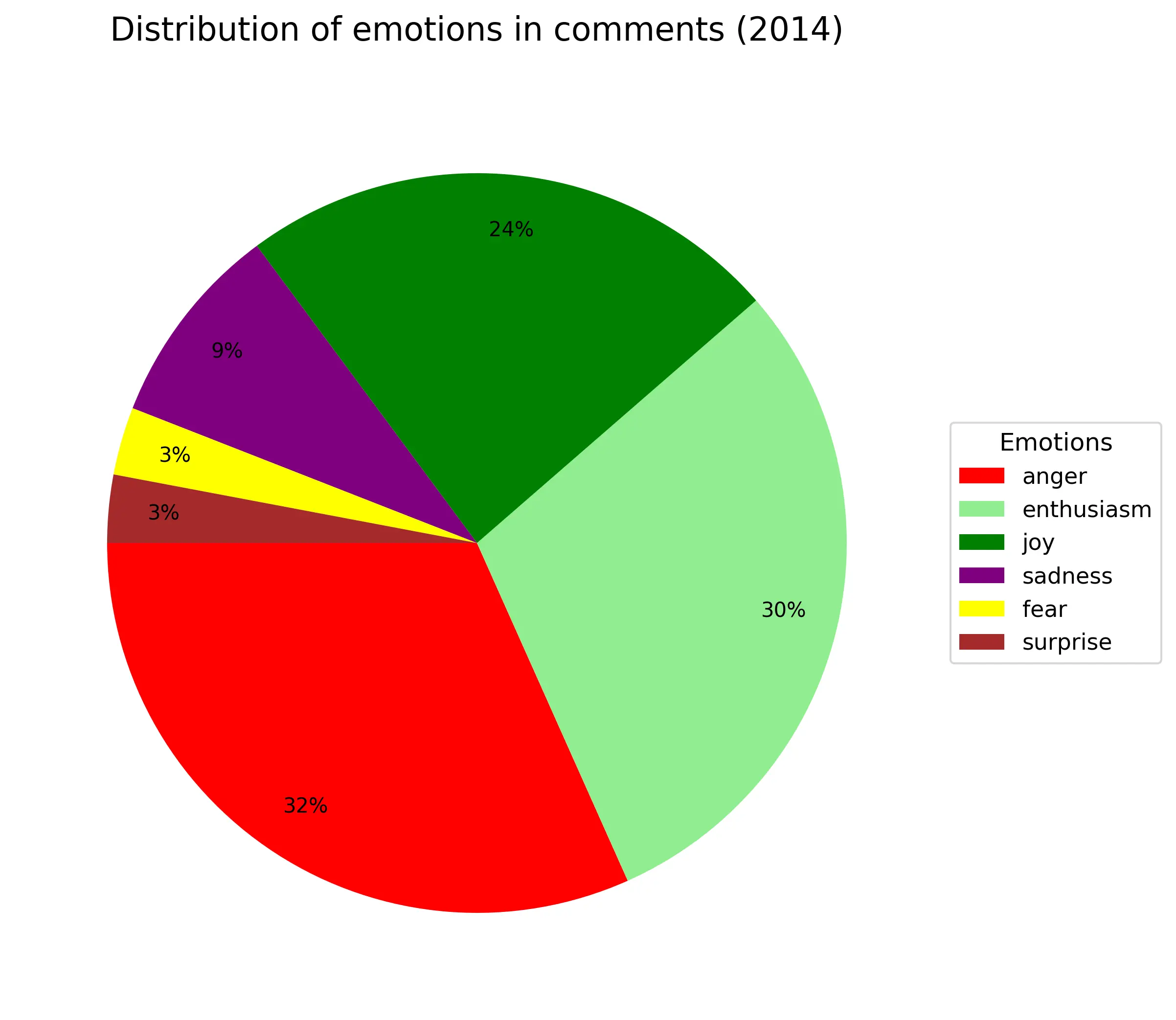
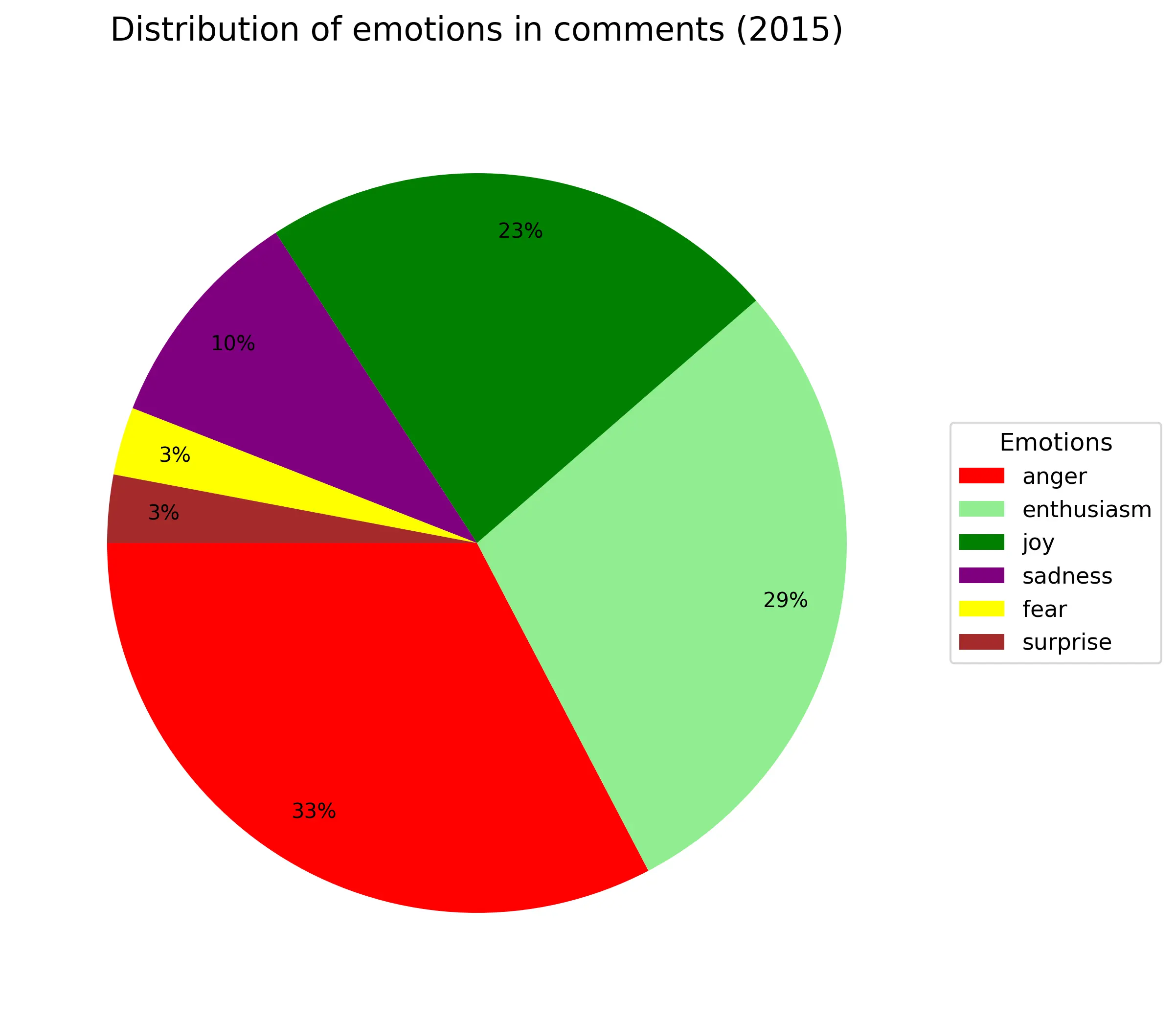
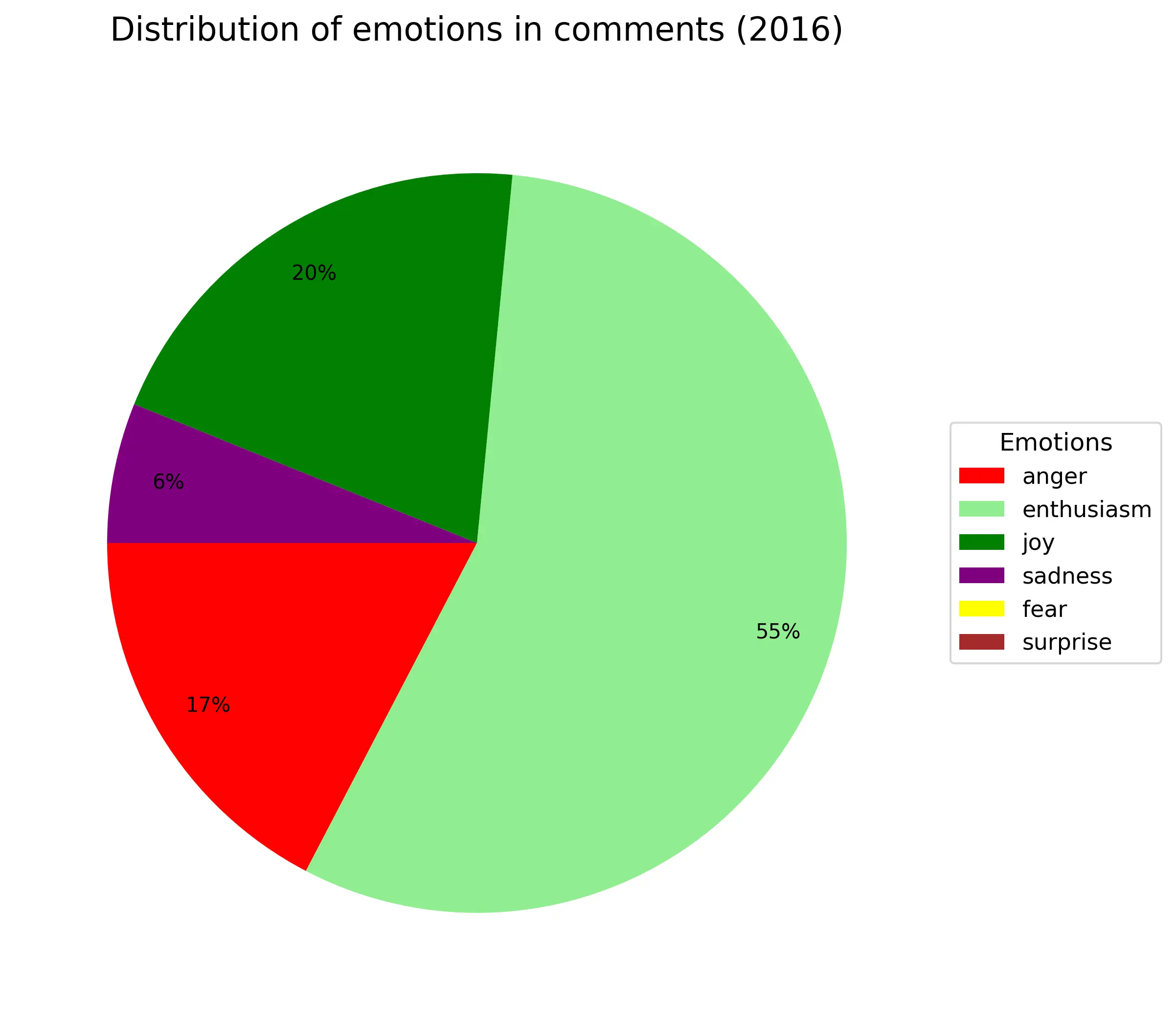
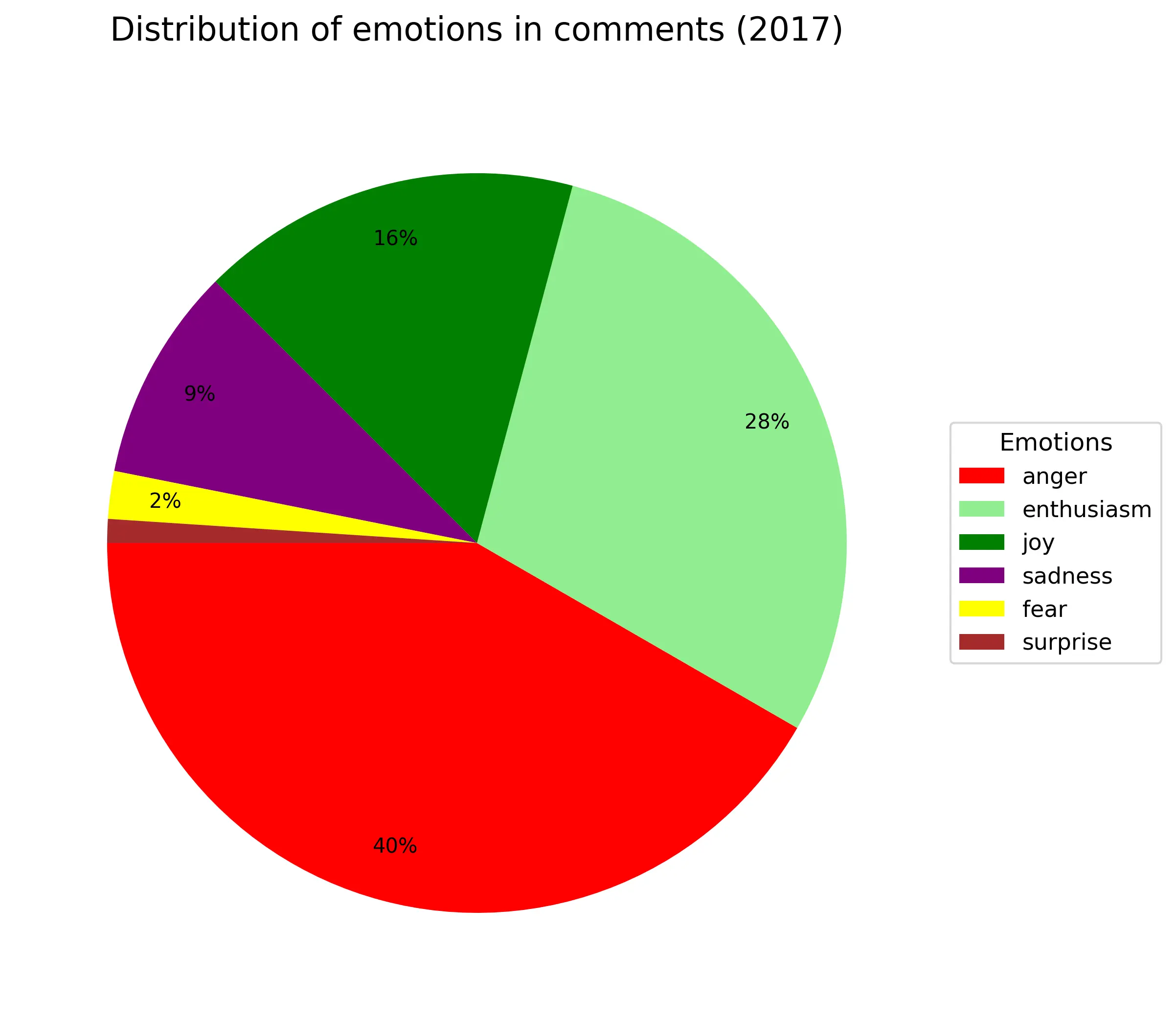
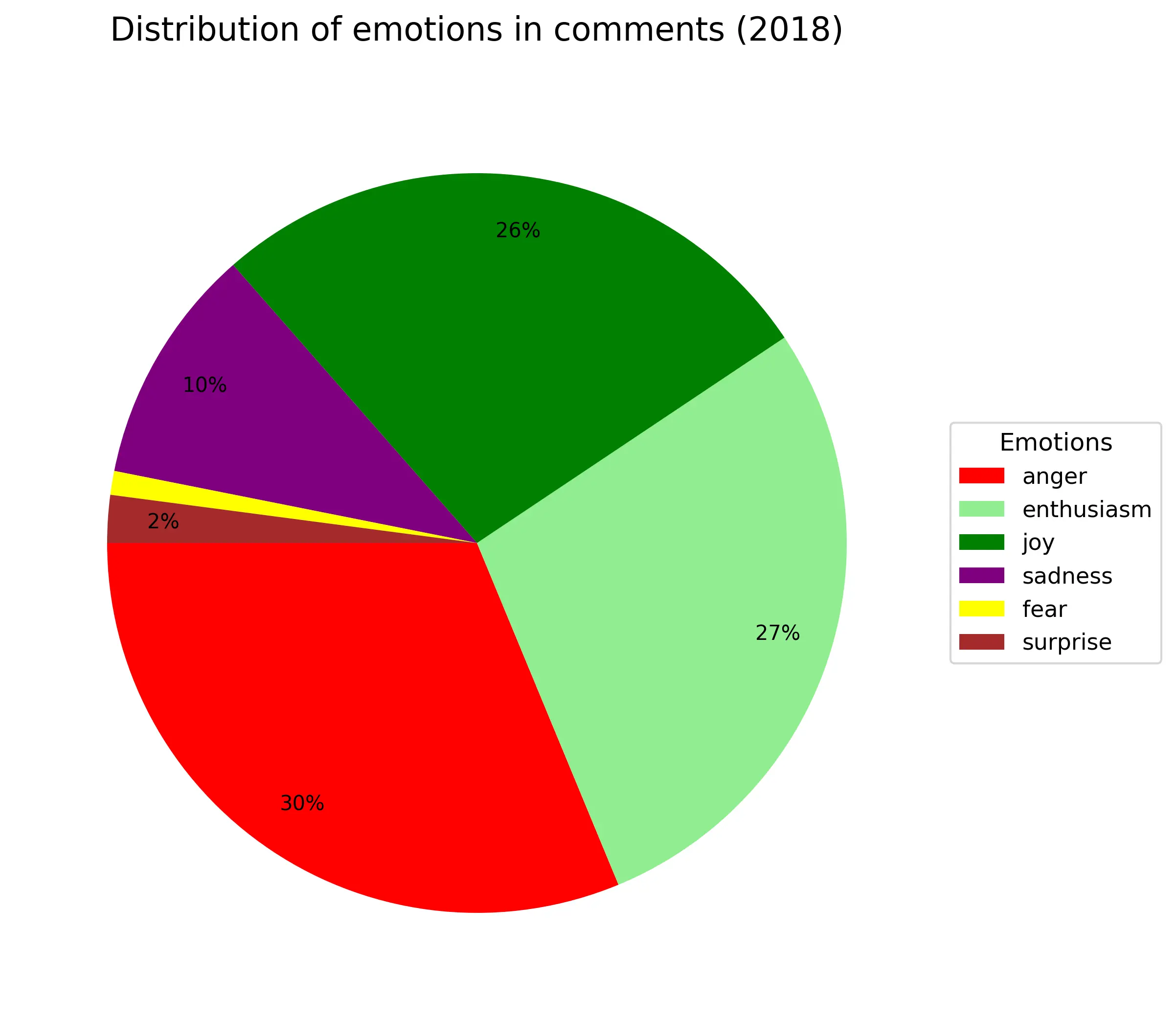
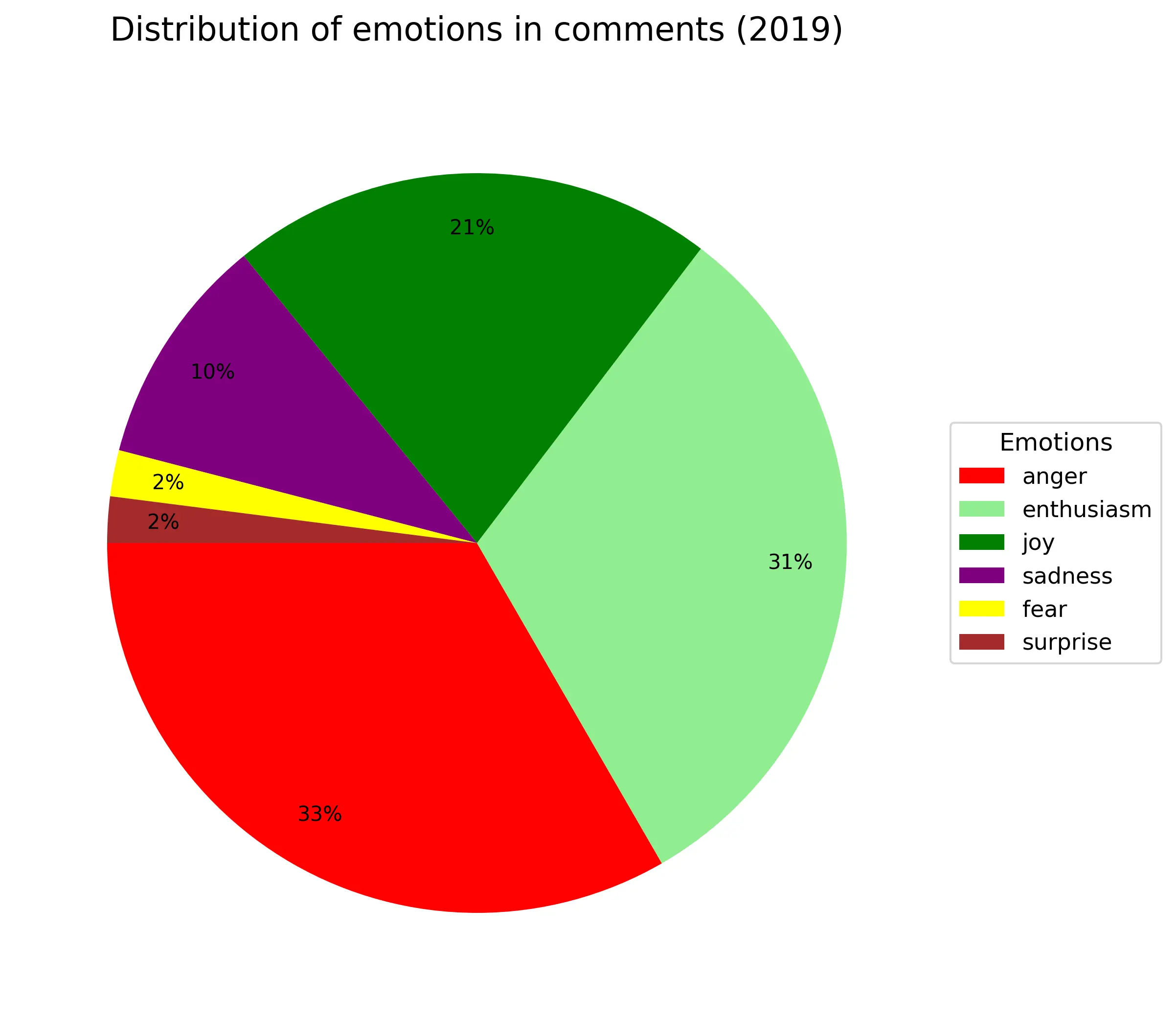
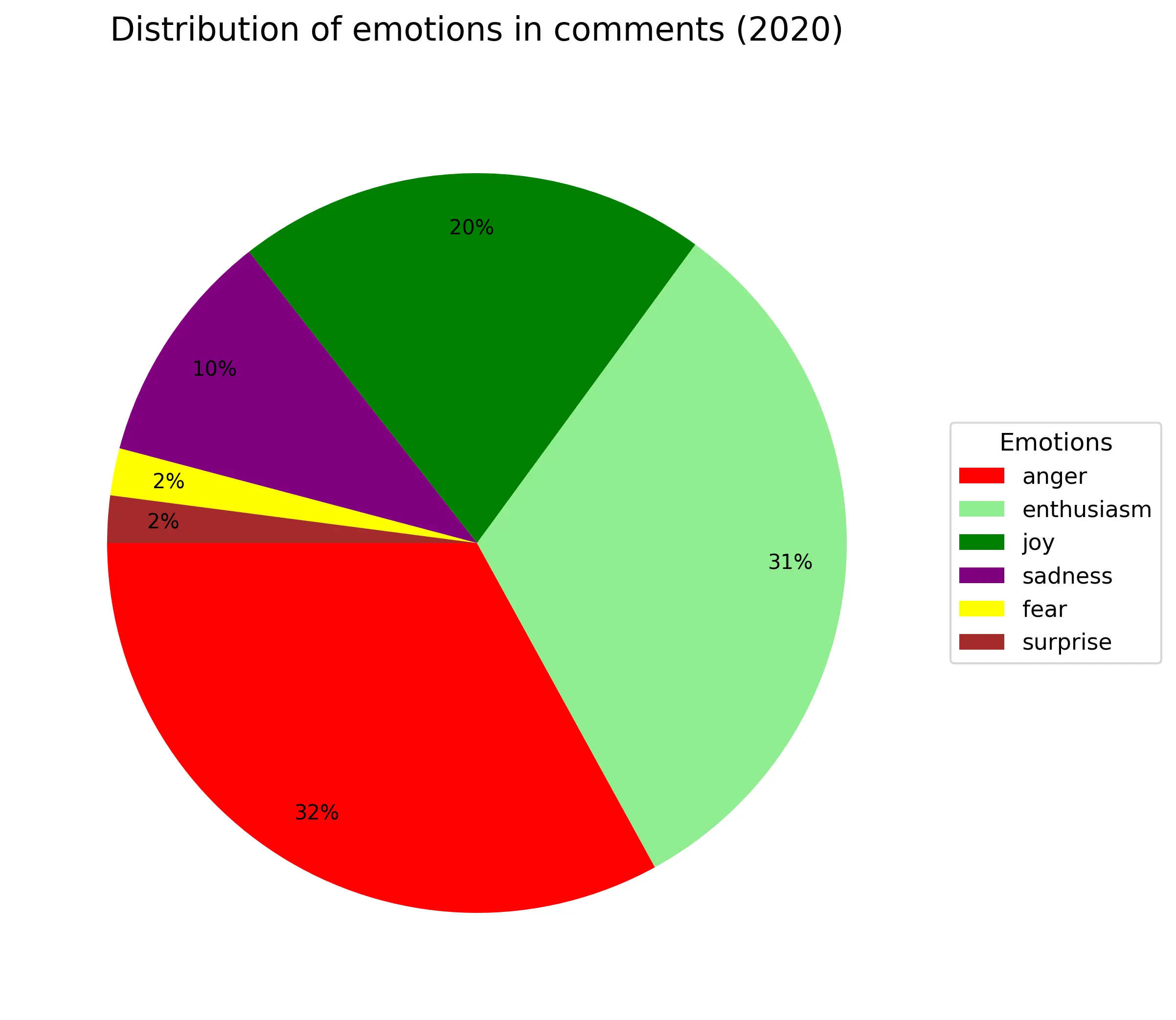
Где-то 1/4-1/3 всех комментариев всегда агрессивные независимо от года. Энтузиазм(весёлый текст с рассуждением) примерно так же (только в 2016году аномалия из-за критичного недостатка материала). Около 10% - грусть/сожаление. Веселые всегда около +20% (по своей сути они не так сильно отличаются от энтузиазма). Удивленность и страх занимают по 2%. Из-за своей малочисленности в график не попала эмоция отвращения.
По недопустимому содержанию. Оно определяется содержанием в комментарии какой-то табуированной темы независимо от оценки автора.
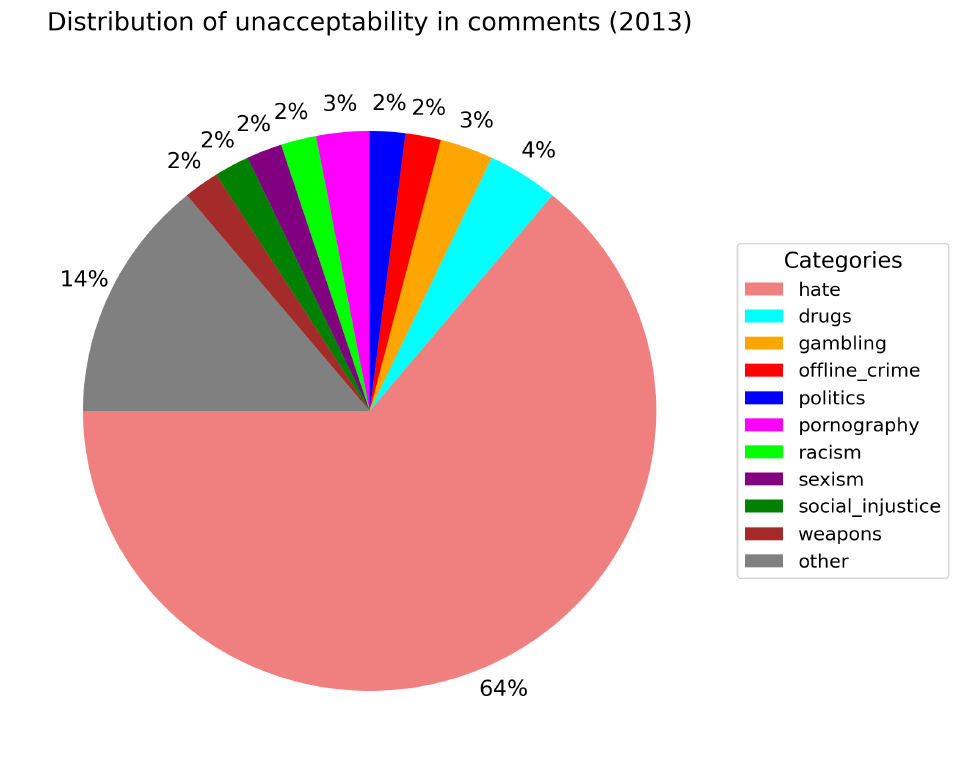
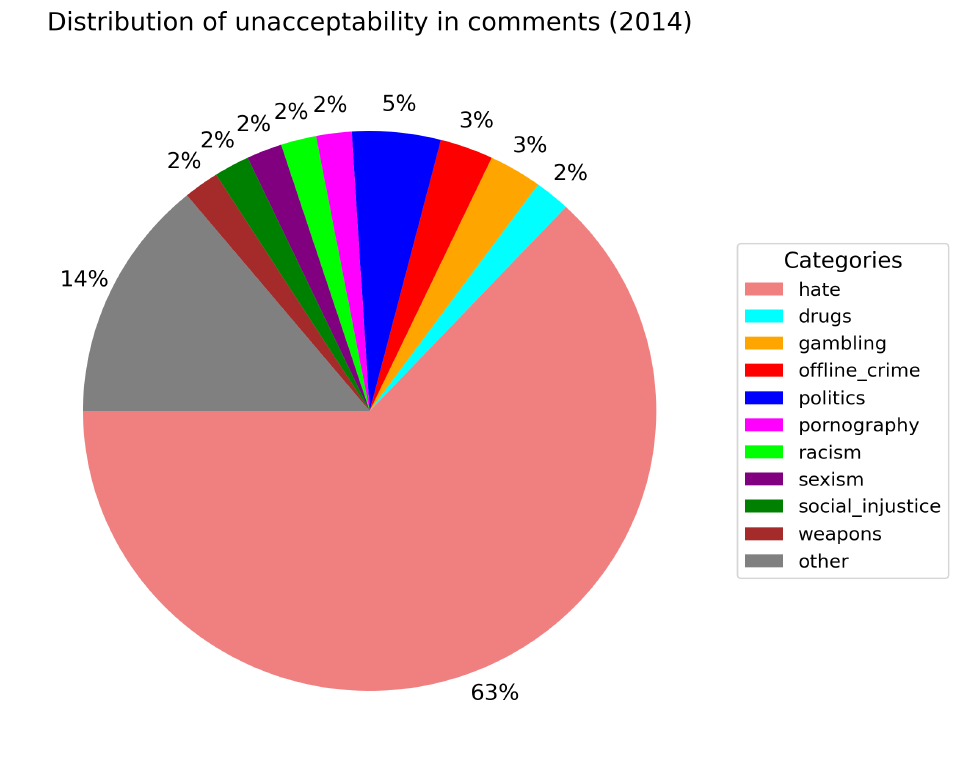
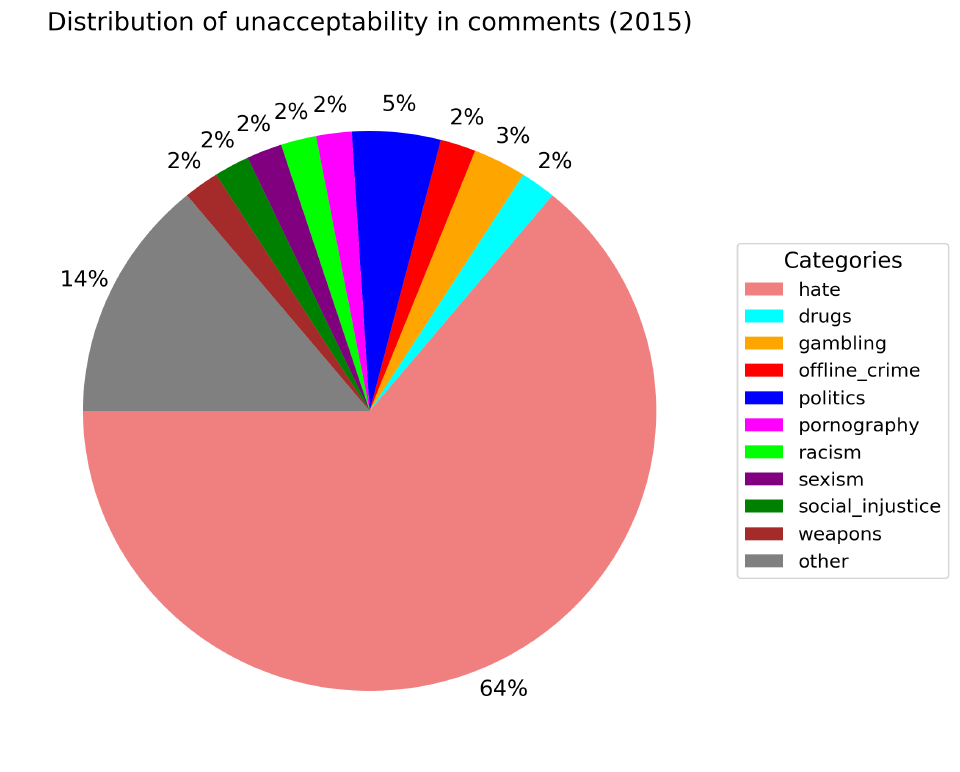
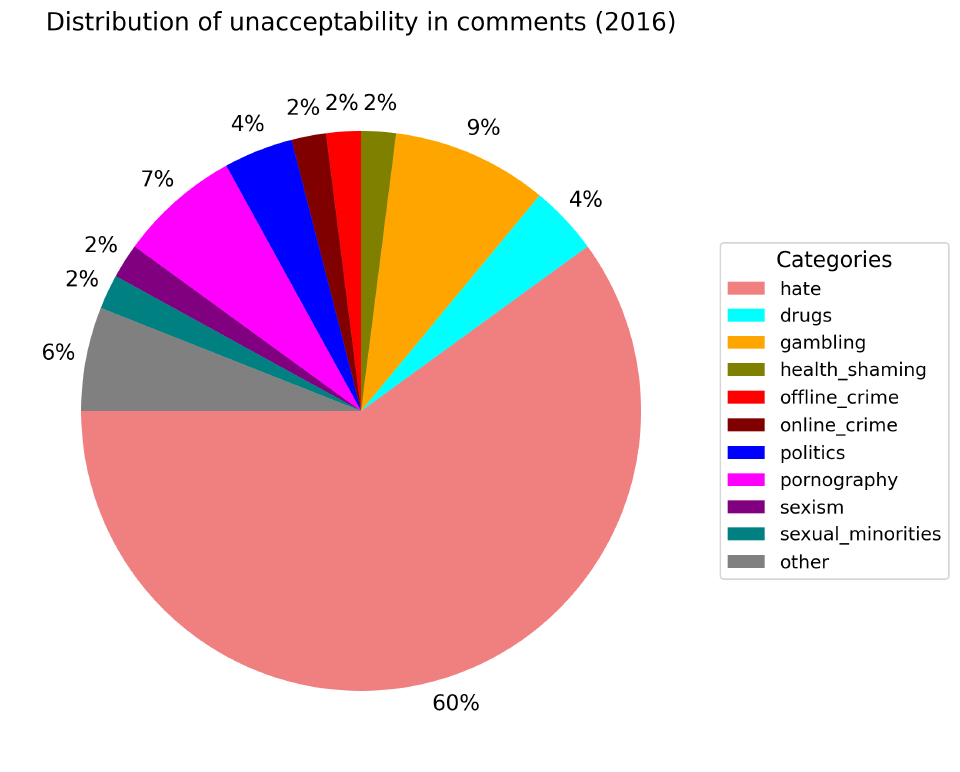
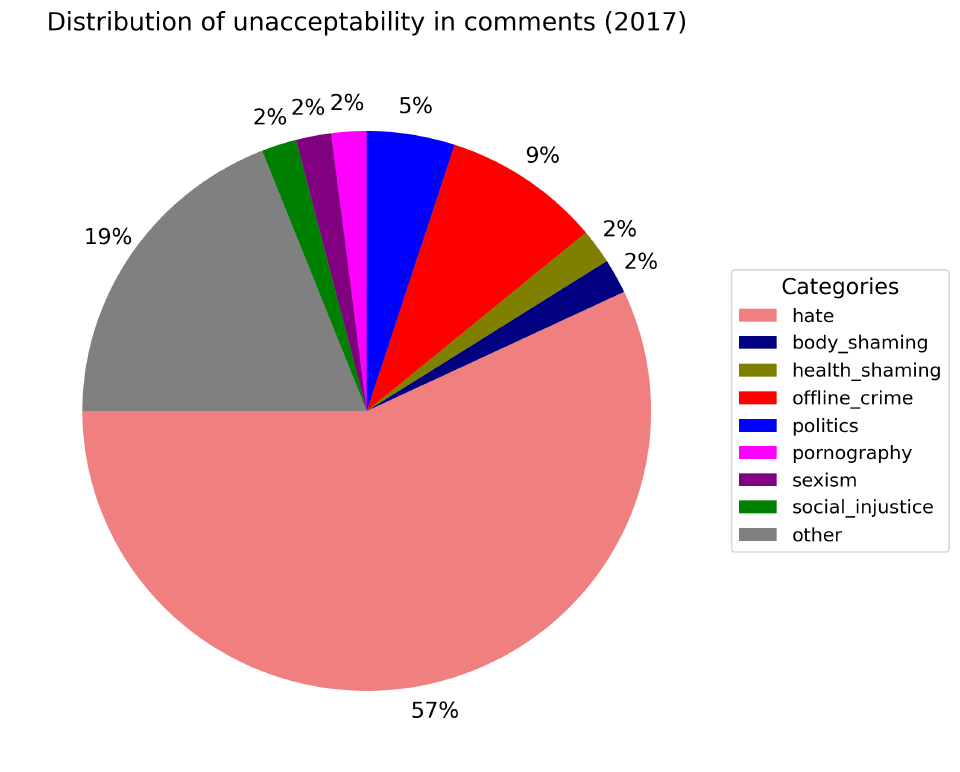
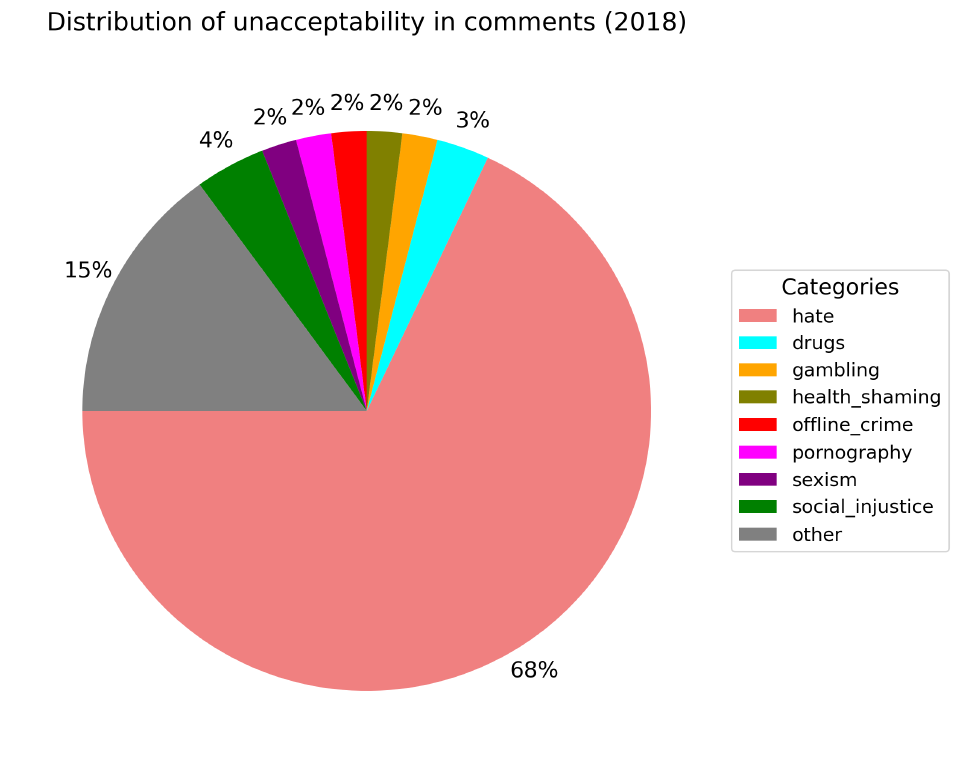
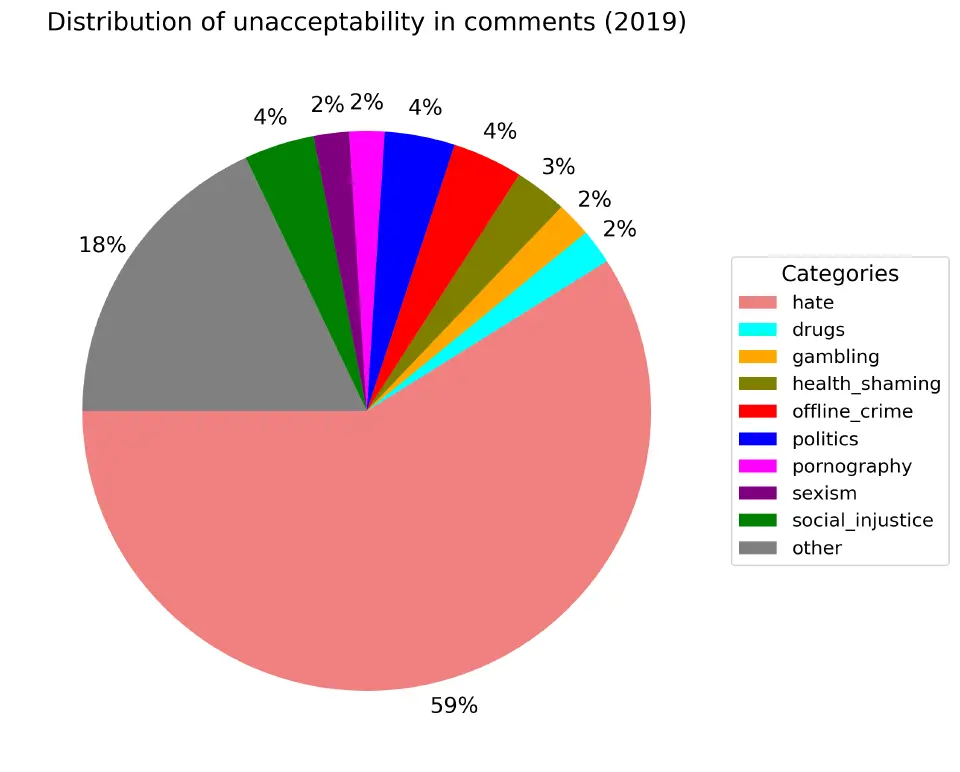
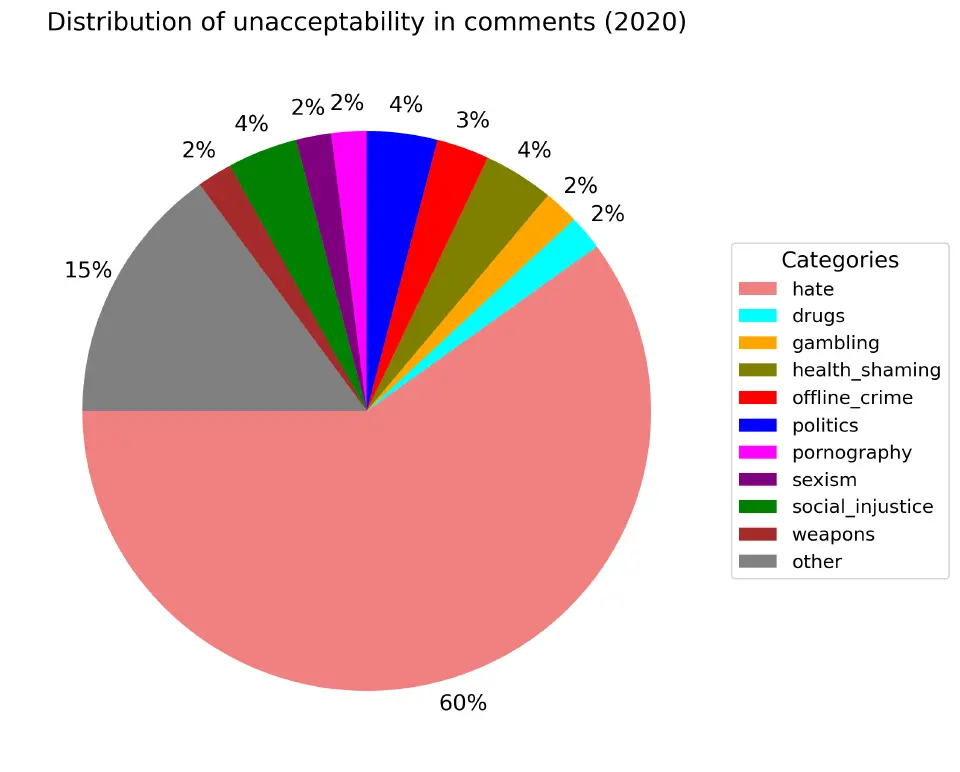
Независимо от года, только 40% комментариев содержат недопустимое содержание. Самые популярные категории: политика (2%-5%), социальная несправедливость (2%-4%) и т.п..
Примечательна аномалия 2017.06 (по факту только этот месяц определяет весь год из-за нехватки данных по нему) связанный с offline_crime (люди очень эмоцианально обсуждали дтп с Марой Багдасарян в Москве).
Если попытаться выявить еще ассоциации в графиках с реальными событиями, то можно взять 2019 год (по нему больше всего данных). Социальная несправедливость один из самых популярных недопустимых тегов, по большей части в нем люди обсуждают цены на еду.
Осуждение здоровья тоже один из популярных тегов, но посмотрев содержание комментариев ничего особенно недопустимого в большинстве не обнаружил (в плане оскорблений и т.п.).